Part of Analytics
Citation Patterns
Statistical analysis of why LLMs cite you or not
What are LLMs and why do they matter for your business?
LLM stands for Large Language Model. These are the artificial intelligence systems behind tools like ChatGPT, Google Gemini, Claude, and Perplexity. They work by processing enormous amounts of text to learn human language patterns, which enables them to answer questions, generate content, and hold natural conversations.
When a user asks ChatGPT "what's the best project management tool?" or asks Perplexity "which laptop should I buy for graphic design?", the LLM analyzes everything it learned from the web and selects the sources it considers most trustworthy to build its response. If your brand, product, or website doesn't have the right signals, the model simply won't include you in that answer, and your competition will take that spot.
Google AI Overviews is Google's version of this technology: instead of showing just a list of links, it now generates a direct AI-powered answer at the top of search results. This means the first result many users see is no longer a link to your site, but an AI-generated response that may or may not mention you.
In short: LLMs are the new intermediaries between your business and your potential customers. More and more people use these tools to research, compare, and decide what to buy. AuraMetrics helps you ensure that when AI answers questions about your industry, your brand is part of the answer.
What it does
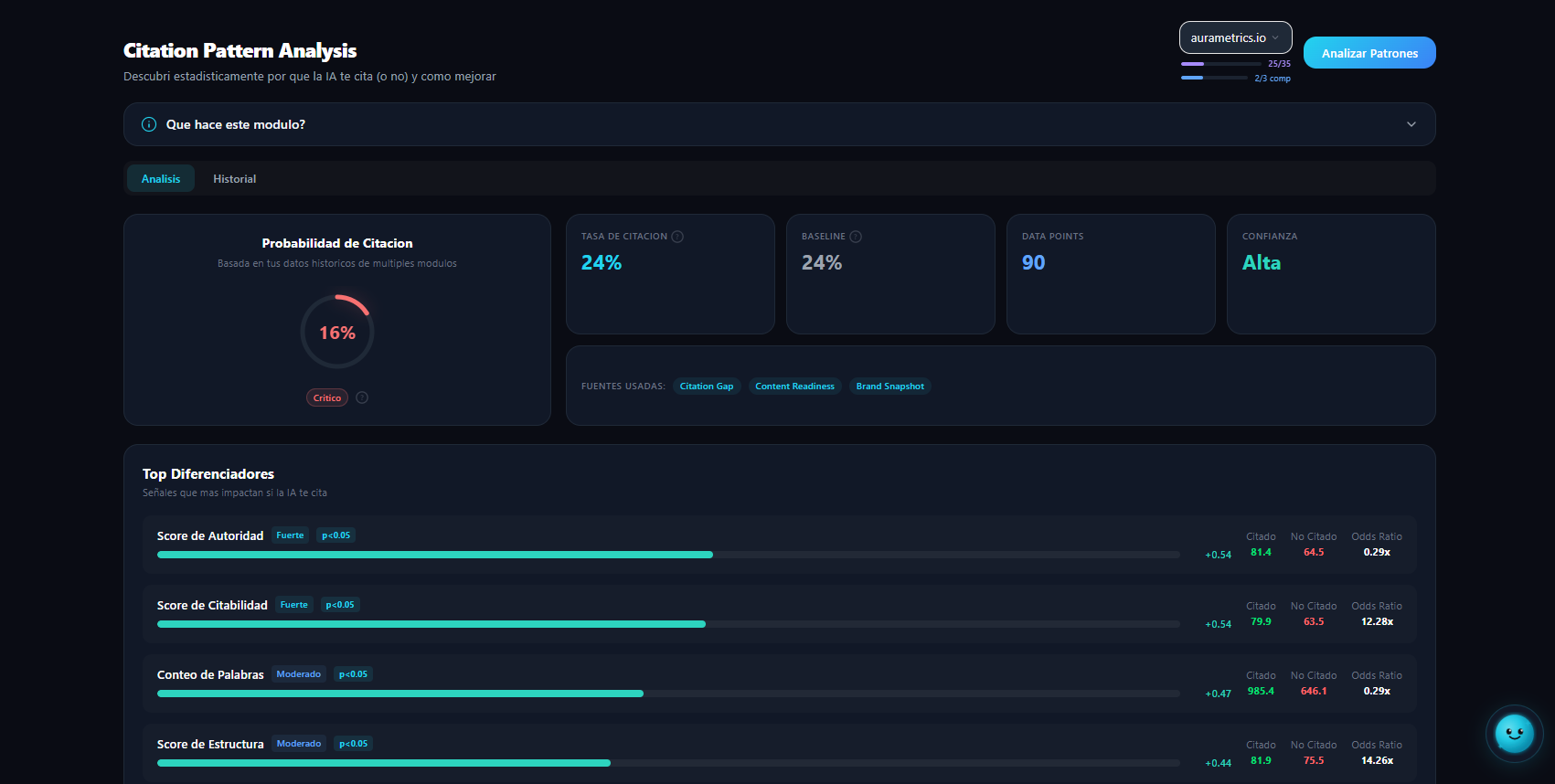
Citation Patterns uses statistical analysis and machine learning to identify which specific signals correlate with higher LLM citation probability in your industry. It's a predictive model that tells you not just IF LLMs will cite you, but WHY they would or wouldn't. Unlike other modules that audit qualitative aspects, Citation Patterns works with quantitative data: correlations, regressions, and improvement scenarios with numerical deltas. It tells you 'if you improve your Schema Completeness from 40 to 70, your citation probability increases by 15%'. The model is continuously trained with data from multiple industries and domains, enabling increasingly precise benchmarks.
Why it matters
Generic recommendations ('improve your schema', 'add trust signals') don't tell you HOW MUCH impact each improvement will have. Citation Patterns gives you concrete numbers based on machine learning. Knowing your citation probability is 35% and that improving Schema Completeness would take it to 50% lets you prioritize with confidence and justify investments to stakeholders with data, not intuition. The model also identifies signals that DON'T matter as much as believed. This prevents you from spending resources on low-return improvements while high-impact quick wins are available.
How it works
Citation Patterns collects your domain's signals (schema, trust, entity, content, citation scores) and compares them with industry benchmarks using a logistic regression model. The model was trained with data from thousands of cross-industry analyses, identifying which signal combinations predict LLM citation. For your domain, it calculates: 1. Citation Probability: estimated probability that an LLM will cite you for queries in your industry 2. Top Differentiators: the signals that most impact your probability (with numerical correlation) 3. Improvement Scenarios: 'what if I improve X' simulations with concrete deltas 4. Signal Contributions: how much each signal contributes (positively or negatively) to your probability The entire process is automatic: you just need a domain with at least 2-3 modules executed.
Metrics you get
Recommended use cases
Frequently asked questions
What is Citation Probability?
An estimated percentage that an LLM will cite your brand when it receives a query relevant to your industry. Calculated with a logistic regression model trained on cross-industry data, comparing your current signals with patterns of cited vs non-cited sites.
How does the machine learning model work?
Uses logistic regression trained on data from thousands of analyses. Model features are your site's signals (schema completeness, trust score, entity clarity, etc.). Output is citation probability. It also calculates feature importance (top differentiators) and simulates improvement scenarios.
What are Top Differentiators?
The signals that most separate cited from non-cited sites in your industry. Each differentiator has a numerical correlation and shows the average of cited vs non-cited sites for that signal. Tells you exactly where to focus.
What are Improvement Scenarios?
'What if' simulations. For example: 'If you improve Schema Completeness from 40 to 70, your Citation Probability goes from 35% to 50% (+15 points)'. Each scenario includes the expected delta and estimated effort.
How reliable is the prediction?
The Confidence Level indicates how certain the model is. It depends on the amount of data available for your industry and how many modules you've run. More data means higher confidence. The model typically has 70-85% accuracy in cross-validation.
Do I need to run other modules first?
Citation Patterns works best with data from at least 3-4 executed modules (Content Readiness, AI Understanding, Schema Validator, Trust Auditor). The more signals the model has, the more precise the prediction.
Does the model update?
Yes. The model is periodically retrained with new analysis data, which improves precision over time. Every time you run Citation Patterns, you use the most recent model version.
How is it different from AI Visibility Gaps?
AI Visibility Gaps analyzes WHERE you lose citations against competitors (which queries, which competitors). Citation Patterns analyzes WHY statistically: which technical signals on your site correlate with higher or lower citation probability.